wishing you and your family a Merry Christmas and a very Happy New Year ahead. May the season of delight and merriment fill your lives with happiness and prosperity. I would like say thanks to you for reviewing my blog.
Be a part of the endless Technology fun with me and keep enjoying happy coding...
From
Raviraj
### Coding might be so easy as opening a beer can !!! ###
Saturday, December 27, 2008
Monday, December 22, 2008
Codeigniter 's Flexibility Part-1
I am looking to test Codeigniter 's Flexibility... actually there are few points that cause me to deep dive in codeigniter.
1. Can we keep associated views/controllers/models in the same folder ?
i.e.
2. Can we load and render one controller from within another controller ?
3. Can we call more than one controller per request in codeigniter project ?
I have looked on net ... did some googling ;) and working on it and got a very good response. Hope will get success very soon, till then happy coding and enjoy winter weather...
1. Can we keep associated views/controllers/models in the same folder ?
i.e.
/system/application/modules/MODULENAME/controllers//system/application/modules/MODULENAME/models//system/application/modules/MODULENAME/views/ 3. Can we call more than one controller per request in codeigniter project ?
I have looked on net ... did some googling ;) and working on it and got a very good response. Hope will get success very soon, till then happy coding and enjoy winter weather...
Goodbye 2008 and welcome 2009
2008 was a very interesting year for me, with both failures and successes. 2009 will be a very interesting year for mobility and handsets and applications.
Here are few predictions about mobility and 2009 ( That i searched over internet).
1. The role of Open Source Software (OSS) will continue to grow within mobile handsets and software. Symbian will go open source. Android is open source. Browsers are open source. Windows Mobile I’m not sure but I won’t be surprised if they go open source as well. Device manufacturers will deliver more sophisticated handsets cheaper due to OSS.
2. On user interfaces and smartphones, touch-screens and gestures and accelerometers will be the rule, not the exception (thank you Apple).
3. For Social Networking .. i think 2009 will not be so good. i think “everyone loves social software, but few would pay for it”.
4. Google will introduce a checkout process for its app store, and developers wanting to make money will notice; the Google app store will explode with a large number of applications.
5. he top smartphone platforms for 2009 will be: iPhone, Android, and BlackBerry (for both mobile web and local apps).
6. Network providers will start delivering services of their own on the web (similar to Google services).
7. Network providers will show their love to widgets, and spend resources on widget-related approaches to applications and user interfaces.
Well .. above are not professional advise for business or personal decisions. :)
Here are few predictions about mobility and 2009 ( That i searched over internet).
1. The role of Open Source Software (OSS) will continue to grow within mobile handsets and software. Symbian will go open source. Android is open source. Browsers are open source. Windows Mobile I’m not sure but I won’t be surprised if they go open source as well. Device manufacturers will deliver more sophisticated handsets cheaper due to OSS.
2. On user interfaces and smartphones, touch-screens and gestures and accelerometers will be the rule, not the exception (thank you Apple).
3. For Social Networking .. i think 2009 will not be so good. i think “everyone loves social software, but few would pay for it”.
4. Google will introduce a checkout process for its app store, and developers wanting to make money will notice; the Google app store will explode with a large number of applications.
5. he top smartphone platforms for 2009 will be: iPhone, Android, and BlackBerry (for both mobile web and local apps).
6. Network providers will start delivering services of their own on the web (similar to Google services).
7. Network providers will show their love to widgets, and spend resources on widget-related approaches to applications and user interfaces.
Well .. above are not professional advise for business or personal decisions. :)
Saturday, December 20, 2008
Which Javascript frameworks are the most common and why ?
The frameworks i looked for this article were Prototype, JQuery, MooTools, Yahoo! UI Library, Dojo, ExtJS and MochiKit.
Prototype
Prototype turned out to be the most-used framework in this survey, and of course it takes cake but JQuery not far behind. Please see following links regarding who is best.
http://blog.solnic.eu/2007/11/11/jquery-vs-prototype-part-i
http://blog.solnic.eu/2008/2/3/jquery-vs-prototype-part-ii
finally i must say that Jquery and prototype are both great libraries. I think now jQuery's philosophy (type less, do more, keeping things intuitive and unobtrusive) will make a big difference.
size is always a concern. Most important is speed :) and again prototype got success here.
we can get it as a 14.4kb gzipped version file.
http://groups.google.com/group/prototype-core/browse_thread/thread/ef05ede819727d52
http://ajax.googleapis.com/ajax/libs/prototype/1.6.0.3/prototype.js
http://groups.google.com/group/prototype-core
but at last we can not close eyes. i think now Jquery is really starting to overtake prototype and prototype is losing ground. No matter how great of a library is, with the current strategy , this fantastic lib will not survive.prototype should have components not a whole lot but atleast a few basic ones like jquery’s tabs, accordion ect.. i request to prototype dev team to do something about it because people are starting to get woried !!!
Prototype
Prototype is one of the earlier Javascript frameworks.Of the websites in this test, a total of 13 used the Prototype framework.
- CNN
- The New York Times
- Digg
- Apple
- Veoh.com
- TypePad
- Fox News Channel
- Finetune
- iLike
- Last.fm
- Hakia
- YouSendIt
JQuery is a framework that has received a lot of attention due to its speed, size and smart modular approach which has led to a big library of plugins. Of the websites in this test, 11 used the JQuery framework.
MooToolsJust like other Javascript frameworks, MooTools contains several functions to help development. One of the more known ones is its advanced effects component. Of the websites in this test, four used the MooTools frameworks.
Yahoo! UI Library (YUI)Yahoo has developed its own Javascript framework. They use it for their own websites, but have also made it freely available to others. Of the websites in this test, seven used the Yahoo! UI Library.
The ones using more than one framework were Digg (Prototype and JQuery), Bebo (MooTools and YUI) and YouSendIt (Prototype and YUI).Prototype turned out to be the most-used framework in this survey, and of course it takes cake but JQuery not far behind. Please see following links regarding who is best.
http://blog.solnic.eu/2007/11/11/jquery-vs-prototype-part-i
http://blog.solnic.eu/2008/2/3/jquery-vs-prototype-part-ii
finally i must say that Jquery and prototype are both great libraries. I think now jQuery's philosophy (type less, do more, keeping things intuitive and unobtrusive) will make a big difference.
size is always a concern. Most important is speed :) and again prototype got success here.
we can get it as a 14.4kb gzipped version file.
http://groups.google.com/group/prototype-core/browse_thread/thread/ef05ede819727d52
http://ajax.googleapis.com/ajax/libs/prototype/1.6.0.3/prototype.js
http://groups.google.com/group/prototype-core
but at last we can not close eyes. i think now Jquery is really starting to overtake prototype and prototype is losing ground. No matter how great of a library is, with the current strategy , this fantastic lib will not survive.prototype should have components not a whole lot but atleast a few basic ones like jquery’s tabs, accordion ect.. i request to prototype dev team to do something about it because people are starting to get woried !!!
Friday, December 19, 2008
APD - Advanced PHP Debugger
APD is a debugger written in C . It loads as an extension to the Zend Engine. It works by hooking into the Zend internals and intercepting PHP function calls, allowing it to do things like measure function execution time, count function calls, perform stack backtraces and other things.
Installing APD
Currently, three main ways exist to install APD on a Linux system: grab the source and compile it yourself, use PEAR or use the Debian package.
1. pecl install apd
2. Edit php.ini file
zend_extension = /usr/lib/php/modules/apd.so
apd.dumpdir = /var/log/pprof
3. Don't forget restart Apache :)
Test & debugging
First make sure APD is is installed properly ... for this check phpinfo() API. Now add apd_set_pprof_trace() API where you would like debug.
Gathering Some Data
Look at apd.dumpdir folder . pprof tracefile has been written out here. A pprof tracefile is a text file that contains a machine-parsable summary of how your PHP was processed. suppose output file is pprof.08871.0 ,The number is the process ID of the Web server process that handled the request.
Interpreting The pprof Tracefile
APD comes with a little shell script written in PHP, called pprofp, that can be run from the command line to parse the pprof tracefile and give you a human-readable report. To use it, run pprofp and pass it an option and the path of the tracefile, like this:-
pprofp -u /var/log/pprof/pprof.25802
-a: sort by alphabetic names of subroutines.
-l: sort by number of calls to subroutines.
-m: sort by memory used in a function call.
-r: sort by real time spent in subroutines.
-R: sort by real time spent in subroutines (inclusive of child calls).
-s: sort by system time spent in subroutines.
-S: sort by system time spent in subroutines (inclusive of child calls).
-u: sort by user time spent in subroutines.
-U: sort by user time spent in subroutines (inclusive of child calls).
-v: sort by average amount of time spent in subroutines.
-z: sort by user+system time spent in subroutines. (default)
if you found any difficulty , then use kcachegrind tool ... it's free tool and probably installed on each machine.
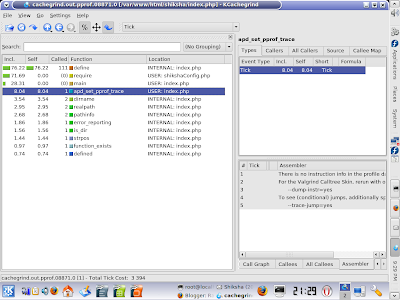
1. pprof2calltree -f pprof.08871.0 ( it will return a file that is readable by kcachegrind ).
2. kcachegrind cachegrind.out.pprof.08871.0 report will shown like this ...
Links:-
http://in.php.net/apd
Installing APD
Currently, three main ways exist to install APD on a Linux system: grab the source and compile it yourself, use PEAR or use the Debian package.
1. pecl install apd
2. Edit php.ini file
zend_extension = /usr/lib/php/modules/apd.so
apd.dumpdir = /var/log/pprof
3. Don't forget restart Apache :)
Test & debugging
First make sure APD is is installed properly ... for this check phpinfo() API. Now add apd_set_pprof_trace() API where you would like debug.
Gathering Some Data
Look at apd.dumpdir folder . pprof tracefile has been written out here. A pprof tracefile is a text file that contains a machine-parsable summary of how your PHP was processed. suppose output file is pprof.08871.0 ,The number is the process ID of the Web server process that handled the request.
Interpreting The pprof Tracefile
APD comes with a little shell script written in PHP, called pprofp, that can be run from the command line to parse the pprof tracefile and give you a human-readable report. To use it, run pprofp and pass it an option and the path of the tracefile, like this:-
pprofp -u /var/log/pprof/pprof.25802
-a: sort by alphabetic names of subroutines.
-l: sort by number of calls to subroutines.
-m: sort by memory used in a function call.
-r: sort by real time spent in subroutines.
-R: sort by real time spent in subroutines (inclusive of child calls).
-s: sort by system time spent in subroutines.
-S: sort by system time spent in subroutines (inclusive of child calls).
-u: sort by user time spent in subroutines.
-U: sort by user time spent in subroutines (inclusive of child calls).
-v: sort by average amount of time spent in subroutines.
-z: sort by user+system time spent in subroutines. (default)
if you found any difficulty , then use kcachegrind tool ... it's free tool and probably installed on each machine.
1. pprof2calltree -f pprof.08871.0 ( it will return a file that is readable by kcachegrind ).
2. kcachegrind cachegrind.out.pprof.08871.0 report will shown like this ...

Links:-
http://in.php.net/apd
Thursday, December 18, 2008
Optimizing MySQL database
well , we have seen so many articles on Mysql performance and optimization. In this article i am trying to summarized all key points. hope this will help to developers and make life easier. :)
How MySQL stores data ?
Databases are stored as directories.
Tables are stored as files.
Columns are stored in the files in dynamic length or fixed size format. In BDB tables the data is stored in pages.
Memory-based tables are supported.
Databases and tables can be symbolically linked from different disks.
On Windows MySQL supports internal symbolic links to databases with .sym files.
MySQL table types
HEAP tables; Fixed row size tables that are only stored in memory and indexed with a HASH index.
ISAM tables; The old B-tree table format in MySQL 3.22.
MyISAM tables; New version of the ISAM tables with a lot of extensions:
Binary portability.
Index on NULL columns.
Less fragmentation for dynamic-size rows than ISAM tables.
Support for big files.
Better index compression.
Better key statistics.
Better and faster auto_increment handling.
Berkeley DB (BDB) tables from Sleepycat: Transaction-safe (with BEGIN WORK / COMMIT | ROLLBACK).
MySQL row types (only relevant for ISAM/MyISAM tables)
MySQL will create the table in fixed size table format if all columns are of fixed length format (no VARCHAR, BLOB or TEXT columns). If not, the table is created in dynamic-size format.
Fixed-size format is much faster and more secure than the dynamic format.
The dynamic-size row format normally takes up less space but may be fragmented over time if the table is updated a lot.
In some cases it's worth it to move all VARCHAR, BLOB and TEXT columns to another table just to get more speed on the main table.
With myisampack (pack_isam for ISAM) one can create a read-only, packed table. This minimizes disk usage which is very nice when using slow disks. The packed tables are perfect to use on log tables which one will not update anymore.
MySQL caches (shared between all threads, allocated once)
Key cache ; key_buffer_size, default 8M
Table cache ; table_cache, default 64
Thread cache ; thread_cache_size, default 0.
Hostname cache ; Changeable at compile time, default 128.
Memory mapped tables ; Currently only used for compressed tables.
How the MySQL table cache works
Each open instance of a MyISAM table uses an index file and a data file. If a table is used by two threads or used twice in the same query, MyISAM will share the index file but will open another instance of the data file.
The cache will temporarily grow larger than the table cache size if all tables in the cache are in use. If this happens, the next table that is released will be closed.
You can check if your table cache is too small by checking the mysqld variable Opened_tables. If this value is high you should increase your table cache!
Optimizing hardware for MySQL
- If you need big tables ( > 2G), you should consider using 64 bit hardware like Alpha, Sparc or the upcoming IA64. As MySQL uses a lot of 64 bit integers internally, 64 bit CPUs will give much better performance.
- For large databases, the optimization order is normally RAM, Fast disks, CPU power.
More RAM can speed up key updates by keeping most of the used key pages in RAM. - If you are not using transaction-safe tables or have big disks and want to avoid long file checks, a UPS is good idea to be able to take the system down nicely in case of a power failure.
- For systems where the database is on a dedicated server, one should look at 1G Ethernet. Latency is as important as throughput.
Optimizing disks
Have one dedicated disk for the system, programs and for temporary files. If you do very many changes, put the update logs and transactions logs on dedicated disks.
Low seek time is important for the database disk; For big tables you can estimate that you will need: log(row_count) / log(index_block_length/3*2/(key_length + data_ptr_length))+1 seeks to find a row. For a table with 500,000 rows indexing a medium int: log(500,000)/log(1024/3*2/(3+4)) +1 = 4 seeks The above index would require: 500,000 * 7 * 3/2 = 5.2M. In real life, most of the blocks will be buffered, so probably only 1-2 seeks are needed.
For writes you will need (as above) 4 seek requests, however, to find where to place the new key, and normally 2 seeks to update the index and write the row.
For REALLY big databases, your application will be bound by the speed of your disk seeks, which increase by N log N as you get more data.
Split databases and tables over different disks. In MySQL you can use symbolic links for this.
Striping disks (RAID 0) will increase both read and write throughput.
Striping with mirroring (RAID 0+1) will give you safety and increase the read speed. Write speed will be slightly lower.
Don't use mirroring or RAID (except RAID 0) on the disk for temporary files or for data that can be easily re-generated..
On Linux use hdparm -m16 -d1 on the disks on boot to enable reading/writing of multiple sectors at a time, and DMA. This may increase the response time by 5-50 %.
On Linux, mount the disks with async (default) and noatime.
For some specific application, one may want to have a ram disk for some very specific tables, but normally this is not needed.
Optimizing OS
If you have memory problems, add more RAM instead or configure your system to use less memory.
Don't use NFS disks for data (you will have problems with NFS locking).
Increase number of open files for system and for the SQL server. (add ulimit -n # in the safe_mysqld script).
Increase the number of processes and threads for the system.
If you have relatively few big tables, tell your file system to not break up the file on different cylinders (Solaris).
Use file systems that support big files (Solaris).
Choose which file system to use; Reiserfs on Linux is very fast for open, read and write. File checks take just a couple of seconds.
If possible, run OPTIMIZE table once in a while. This is especially important on variable size rows that are updated a lot.
Update the key distribution statistics in your tables once in a while with myisamchk -a; Remember to take down MySQL before doing this!
If you get fragmented files, it may be worth it to copy all files to another disk, clear the old disk and copy the files back.
If you have problems, check your tables with myisamchk or CHECK table.
Monitor MySQL status with: mysqladmin -i10 processlist extended-status
With the MySQL GUI client you can monitor the process list and the status in different windows.
Use mysqladmin debug to get information about locks and performance.
Optimizing SQL
Use SQL for the things it's good at, and do other things in your application. Use the SQL server to:
Find rows based on WHERE clause.
JOIN tables
GROUP BY
ORDER BY
DISTINCT
Don't use an SQL server:
To validate data (like date)
As a calculator
Tips:
Use keys wisely.
Keys are good for searches, but bad for inserts / updates of key columns.
Keep by data in the 3rd normal database form, but don't be afraid of duplicating information or creating summary tables if you need more speed.
Instead of doing a lot of GROUP BYs on a big table, create summary tables of the big table and query this instead.
UPDATE table set count=count+1 where key_column=constant is very fast!
For log tables, it's probably better to generate summary tables from them once in a while than try to keep the summary tables live.
Take advantage of default values on INSERT.
Optimizing tables
MySQL has a rich set of different types. You should try to use the most efficient type for each column.
The ANALYSE procedure can help you find the optimal types for a table: SELECT * FROM table_name PROCEDURE ANALYSE()
Use NOT NULL for columns which will not store null values. This is particularly important for columns which you index.
Change your ISAM tables to MyISAM.
If possible, create your tables with a fixed table format.
Don't create indexes you are not going to use.
Use the fact that MySQL can search on a prefix of an index; If you have and INDEX (a,b), you don't need an index on (a).
Instead of creating an index on long CHAR/VARCHAR column, index just a prefix of the column to save space. CREATE TABLE table_name (hostname CHAR(255) not null, index(hostname(10)))
Use the most efficient table type for each table.
Columns with identical information in different tables should be declared identically and have identical names.
MySQL extensions / optimization that gives you speed
Use the optimal table type (HEAP, MyISAM, or BDB tables).
Use optimal columns for your data.
Use fixed row size if possible.
Use the different lock types (SELECT HIGH_PRIORITY, INSERT LOW_PRIORITY)
Auto_increment
REPLACE (REPLACE INTO table_name VALUES (...))
INSERT DELAYED
LOAD DATA INFILE / LOAD_FILE()
Use multi-row INSERT to insert many rows at a time.
SELECT INTO OUTFILE
LEFT JOIN, STRAIGHT JOIN
LEFT JOIN combined with IS NULL
ORDER BY can use keys in some cases.
If you only query columns that are in one index, only the index tree will be used to resolve the query.
Joins are normally faster than subselects (this is true for most SQL servers).
LIMIT
SELECT * from table1 WHERE a > 10 LIMIT 10,20
DELETE * from table1 WHERE a > 10 LIMIT 10
foo IN (list of constants) is very optimized.
GET_LOCK()/RELEASE_LOCK()
LOCK TABLES
INSERT and SELECT can run concurrently.
UDF functions that can be loaded into a running server.
Compressed read-only tables.
CREATE TEMPORARY TABLE
CREATE TABLE .. SELECT
MyISAM tables with RAID option to split a file over many files to get over the 2G limit on some file system.
Delayed_keys
Replication
When MySQL doesn't use an index
Indexes are NOT used if MySQL can calculate that it will probably be faster to scan the whole table. For example if key_part1 is evenly distributed between 1 and 100, it's not good to use an index in the following query:
SELECT * FROM table_name where key_part1 > 1 and key_part1 <>
If you are using HEAP tables and you don't search on all key parts with =
When you use ORDER BY on a HEAP table
If you are not using the first key part
SELECT * FROM table_name WHERE key_part2=1
If you are using LIKE that starts with a wildcard
SELECT * FROM table_name WHERE key_part1 LIKE '%jani%'
When you search on one index and do an ORDER BY on another
SELECT * from table_name WHERE key_part1 = # ORDER BY key2
Things to avoid with MySQL
Updates to a table or INSERT on a table with deleted rows, combined with SELECTS that take a long time.
HAVING on things you can have in a WHERE clause.
JOINS without using keys or keys which are not unique enough.
JOINS on columns that have different column types.
Using HEAP tables when not using a full key match with =
Forgetting a WHERE clause with UPDATE or DELETE in the MySQL monitor. If you tend to do this, use the --i-am-a-dummy option to the mysq client.
Tricks to give MySQL more information to solve things better
SELECT SQL_BUFFER_RESULTS ...
Will force MySQL to make a temporary result set. As soon as the temporary set is done, all locks on the tables are released. This can help when you get a problem with table locks or when it takes a long time to transfer the result to the client.SELECT SQL_SMALL_RESULT ... GROUP BY ...
To tell the optimizer that the result set will only contain a few rows.SELECT SQL_BIG_RESULT ... GROUP BY ...
To tell the optimizer that the result set will contain many rows.SELECT STRAIGHT_JOIN ...
Forces the optimizer to join the tables in the order in which they are listed in the FROM clause.SELECT ... FROM table_name [USE INDEX (index_list) | IGNORE INDEX (index_list)] table_name2
Forces MySQL to use/ignore the listed indexes.
General tips:
Use short primary keys. Use numbers, not strings, when joining tables.
When using multi-part keys, the first part should be the most-used key.
When in doubt, use columns with more duplicates first to get better key compression.
If you run the client and MySQL server on the same machine, use sockets instead of TCP/IP when connecting to MySQL (this can give you up to a 7.5 % improvement). You can do this by specifying no hostname or localhost when connecting to the MySQL server.
Use --skip-locking (default on some OSes) if possible. This will turn off external locking and will give better performance.
Use application-level hashed values instead of using long keys:
SELECT * FROM table_name WHERE hash=MD5(concat(col1,col2)) AND
col_1='constant' AND col_2='constant'
Store BLOB's that you need to access as files in files. Store only the file name in the database.
It is faster to remove all rows than to remove a large part of the rows.
If SQL is not fast enough, take a look at the lower level interfaces to access the data.
Wednesday, December 17, 2008
one more markup editor ...
SmartMarkUP is a lightweight and powerful fancy markup editor.
HTML, CSS, XML, Wiki syntax, BBCode or any other desired markup language can be implemented and/or adjusted as per our preferences and business needs.
http://www.phpcow.com/smartmarkup/
Features:-
* It is completely free and open source
* It is a small script, compressed version weights only 10kb.
* It is completely skin-able we can fit it’s design with your applications easily.
* It can be used from any other script.
* It is self contained and doesn’t depend on any third party scripts. we can use it with Prototype, jQuery, Mootools or any other JavaScript libraries.
* It doesn’t requires changing of already existing markup or code infrastructure.
* It degrades gracefully, that means our application will continue working in browsers with disabled JavaScript.
HTML, CSS, XML, Wiki syntax, BBCode or any other desired markup language can be implemented and/or adjusted as per our preferences and business needs.
http://www.phpcow.com/smartmarkup/
Features:-
* It is completely free and open source
* It is a small script, compressed version weights only 10kb.
* It is completely skin-able we can fit it’s design with your applications easily.
* It can be used from any other script.
* It is self contained and doesn’t depend on any third party scripts. we can use it with Prototype, jQuery, Mootools or any other JavaScript libraries.
* It doesn’t requires changing of already existing markup or code infrastructure.
* It degrades gracefully, that means our application will continue working in browsers with disabled JavaScript.
Monday, December 15, 2008
Apache Virtual Hosts
When Apache is started, it scans the configuration file (/etc/httpd/conf/httpd.conf) to determine its settings. It generates a table of the server's IP addresses with a hash (known as a vhost address set) containing the associated domain names. With the Apache daemon (httpd) running and listening at the appropriate ports (usually just 80), it's ready to receive requests from clients.
When a browser goes looking for a document that a user has requested, it first has a domain name server translate the domain name entered to an IP address. The browser then sends the user's request to the IP address. As of HTTP 1.1, the browser must also send to the web server the domain name that the user entered; it's no longer to be implied. This requirement makes virtual hosting possible. If Apache has no vhosts, it will use the main server's DocumentRoot directory (often set to /var/www/html). However, if Apache has been configured for vhosts, it will compare the client's request to the ServerName of each vhost with the same IP address and port that the request came in on. The accompanying vhost directives of the first ServerName that matches the client's request will be applied.
Within a vhost block--between and tags in httpd.conf--many directives may be given, but only two are typically required: the ServerName and the DocumentRoot directives. The ServerName directive provides the domain name. The DocumentRoot directive sets the root directory for the domain. If Apache finds a vhost with a ServerName that matches a client request, it will look in the root directory specified by the DocumentRoot directive for files. If it finds what was requested, it will send copies to the client.

http://www.onlamp.com/pub/a/apache/2003/07/24/vhosts.html?page=2
When a browser goes looking for a document that a user has requested, it first has a domain name server translate the domain name entered to an IP address. The browser then sends the user's request to the IP address. As of HTTP 1.1, the browser must also send to the web server the domain name that the user entered; it's no longer to be implied. This requirement makes virtual hosting possible. If Apache has no vhosts, it will use the main server's DocumentRoot directory (often set to /var/www/html). However, if Apache has been configured for vhosts, it will compare the client's request to the ServerName of each vhost with the same IP address and port that the request came in on. The accompanying vhost directives of the first ServerName that matches the client's request will be applied.
Within a vhost block--between

http://www.onlamp.com/pub/a/apache/2003/07/24/vhosts.html?page=2
Sunday, December 14, 2008
The world of Object-Oriented Programming and Facts
Before I start my article let me explain that I have searched about OOP so much in web and they all talk about creating a class called 'shape' with various subclasses for 'square', 'circle', 'triangle' etc. This is of absolutely no use when I want to build a system to deal with real-world objects such as 'customer', 'product' and 'invoice' which have corresponding database tables. This has often led me to believe that OOP is therefore unsuitable for building common-or-garden business systems.
After that i found few conclusions and summarized all things that i searched on web. I am sure few of my friends will not agree but i am looking for their feedback ... after all it's (understanding OOPS) a common and serious problem among all quality coders .. ;)
Almost every piece of terminology used in OO seems to mean different things to different people. Some of the arguments which caused this article were:-
What does 'encapsulation' really mean?
What does 'separation of roles' really mean?
What does 'having separate layers' really mean?
What does 'visibility' really mean?
What does 'dependency' really mean?
What does 'object oriented' really mean?
What do I make into a class?
How many objects is too many?
How many objects is too few?
When is an object too big?
When is an object too small?
Whose design patterns should I use?
Which design patterns should I use?
All the while these simple questions do not have simple answers which are universally accepted then it will be impossible to produce software which satisfies everybody. No matter how hard you try someone somewhere will always find a reason to denigrate your efforts. If you use method 'A' then to the followers of method 'A' you are a hero while to the followers of method 'B' you are a heretic. If you switch to method 'B' then the followers of method 'A' will call you a heretic.
The Principles of OOP and Definitions:-
| Writing programs which are oriented around objects. Such programs can take advantage of Encapsulation, Polymorphism, and Inheritance to increase code reuse and decrease code maintenance. | |
| A class is a blueprint, or prototype, that defines the variables and the methods common to all objects of a certain kind. | |
| An instance of a class. A class must be instantiated into an object before it can be used in the software. More than one instance of the same class can be in existence at any one time. | |
| The act of placing data and the operations that perform on that data in the same class. The class then becomes the 'capsule' or container for the data and operations. | |
| The reuse of base classes (superclasses) to form derived classes (subclasses). Methods and properties defined in the superclass are automatically shared by any subclass. | |
| Same interface, different implementation. The ability to substitute one class for another. This means that different classes may contain the same method names, but the result which is returned by each method will be different as the code behind each method (the implementation) is different in each class. | |
| Describes the contents of a module. The degree to which the responsibilities of a single module/component form a meaningful unit. The degree of interaction within a module. Higher cohesion is better. A high cohesion method will be simpler to reuse, and to extend, so it will maximize reusability and extendability. | |
| Describes how modules interact. The degree of mutual interdependence between modules/components. The degree of interaction between two modules. Lower coupling is better. Low coupling tends to create more reusable methods. It is not possible to write completely decoupled methods, otherwise the program will not work! | |
| The ability to 'see' parts of an object from outside. Any method or property marked as 'public' is visible, whereas any method or property marked as 'private/protected' is not visible to the outside world and is therefore 'hidden'. Methods and properties which should not be directly accessed from outside should be hidden. Lower visibility is better. | |
| The degree that one component relies on another to perform its responsibilities. High dependency limits code reuse and makes moving components to new projects difficult. Lower dependency is better. |
Each real-world entity is modeled with its own class containing properties (variables or data) and methods (functions or operations which act upon, or change the 'state' of, those properties).
Reference: What is a Class?
A 'class' is not an 'object', it is the blueprint, pattern or prototype that defines how an object will look and behave when it is created or instantiated from that class. Software must create an object (an instance of a class) before it can access any of its methods (functions) or manipulate any of its properties (data).
Reference: What is an Object?
'Encapsulation' means that the class must define all the properties and methods which are common to all objects of that class. All those properties and methods must exist inside a single container or 'capsule', and must not be distributed across multiple locations.
Reference: encapsulation The localization of knowledge within a module. Because objects encapsulate data and implementation, the user of an object can view the object as a black box that provides services. Instance variables and methods can be added, deleted, or changed, but as long as the services provided by the object remain the same, code that uses the object can continue to use it without being rewritten.
'Implementation Hiding' means that the outside world may know about the properties and methods that exist within a class, but it does not know how each method is actually implemented. This allows the implementation to be changed at any time without the outside world being affected or even knowing that the implementation has changed.
'Inheritance' is where the properties and methods of one class (the 'superclass') are shared by another class (the 'subclass'). The subclass may choose to override any properties or methods defined in the superclass with its own specific variations, or it may choose to add extra properties and methods of its own (i.e. 'extend' the superclass). Inheritance is the mechanism whereby common code is shared between one class and another.
Reference: What is Inheritance?
An 'abstract method' is one which is defined in the superclass as nothing but an empty placeholder. The actual implementation is defined within a subclass. Different subclasses may have different implementations of the same abstract method.
An 'abstract class' is one which cannot be instantiated into an object because it does not contain any implementation details. These missing details must be supplied via a subclass so that the combination of the two, the superclass and the subclass, is then capable of being instantiated into an object. The subclass provides the missing implementation details by overriding methods and/or properties defined within the superclass. Different subclasses may therefore provide different implementation details.
Reference: abstract class A class that contains one or more abstract methods, and therefore can never be instantiated. Abstract classes are defined so that other classes can extend them and make them concrete by implementing the abstract methods.
'Polymorphism' is where different classes may have methods with the same name as other classes, but where the response obtained from those methods is determined by the object itself. In other words: same interface, different implementation; or the ability to substitute one class for another.
Few Facts that should know about encapsulation:-
Encapsulation is the same as Information Hiding.
Information Hiding is the same as Data Hiding.
Data Hiding means not using public variables.
Therefore: Encapsulation is the same as not using public variables. :)
Consider these articles I found after a quick search of the Internet using google and the word 'encapsulation' mean :
Encapsulation is not information hiding by Wm. Paul Rogers of Java World
Abstraction, Encapsulation, and Information Hiding by Edward V. Berard of The Object Agency
Encapsulation Wasn't Meant To Mean Data Hiding by Martin Fowler
Here is a definition of 'data hiding' I found at SearchDatabase.com:
Data hiding is a characteristic of object-oriented programming. Because an object can only be associated with data in predefined classes or templates, the object can only 'know' about the data it needs to know about. There is no possibility that someone maintaining the code may inadvertently point to or otherwise access the wrong data unintentionally. Thus, all data not required by an object can be said to be 'hidden'. Even more off the wall is the idea being touted around in some quarters that inheritance breaks encapsulation (refer to the third paragraph).
What are the benefits of OO Programming?
Advocates of OOP often make brash claims as to why developers should switch from 'old-fashioned' procedural programming to 'new-fangled' object oriented programming. Among these claims are:
Faster development through the use of more reusable code.
Easier maintenance as business logic is not duplicated in multiple places.
and so on, and so on, ...
It is quite clear to me that object oriented programming is anything but simple. What started life with a few simple principles - that of encapsulation, inheritance and polymorphism - has quickly grown into a multi-headed beast which means something totally different to different people. The original definitions have been redefined, re-interpreted, expanded and mutated beyond all recognition.
At Last few links that forced me to write this article:-
The 3 Tier Architecture
Any piece of software can be subdivided into the following areas:-

If you split off all the code that handles the communication with the physical database to a separate component then you have a 2 tier architecture, as shown in snap.

If you go one step further and split the presentation logic from the business logic you have a 3 Tier Architecture, as shown in snap. Note that there is no direct communication between the presentation and data access layers - everything must go through the business layer in the middle.

When this architecture is implemented the benefits will become apparent as more code can be shared instead of being duplicated. Several components in the presentation layer can share the same component in the business layer, and all components in the business layer share the same component in the data access layer.
- Presentation logic = User Interface, displaying data to the user, accepting input from the user.
- Business logic = Business Rules, handles data validation and task-specific behaviour.
- Data Access logic = Database Communication, constructing SQL queries and executing them via the relevant API.

If you split off all the code that handles the communication with the physical database to a separate component then you have a 2 tier architecture, as shown in snap.

If you go one step further and split the presentation logic from the business logic you have a 3 Tier Architecture, as shown in snap. Note that there is no direct communication between the presentation and data access layers - everything must go through the business layer in the middle.

When this architecture is implemented the benefits will become apparent as more code can be shared instead of being duplicated. Several components in the presentation layer can share the same component in the business layer, and all components in the business layer share the same component in the data access layer.
The big advantage of a 3-tier system is that it is possible to change the contents of any one of the tiers/layers without having to make corresponding changes in any of the others. For example:
- A change from one DBMS to another would only require a change to the component in the data access layer.
- A change in the Use Interface, for example from desktop to the web, would only require changes to the components in the presentation layer.
Principles of the MVC Design Pattern
The MVC paradigm is a way of breaking an application, or even just a piece of an application's interface, into three parts: the model, the view, and the controller. MVC was originally developed to map the traditional input, processing, output roles into the GUI realm:-

Input --> Processing --> Output
Controller --> Model --> View
Note that the model may not necessarily have a persistent data store (database), such as when it deals with a control on a GUI screen.
Model
- A model is an object representing data or even activity, e.g. a database table or even some plant-floor production-machine process.
- The model manages the behavior and data of the application domain, responds to requests for information about its state and responds to instructions to change state.
- The model represents enterprise data and the business rules that govern access to and updates of this data. Often the model serves as a software approximation to a real-world process, so simple real-world modeling techniques apply when defining the model.
- The model is the piece that represents the state and low-level behavior of the component. It manages the state and conducts all transformations on that state. The model has no specific knowledge of either its controllers or its views. The system itself maintains links between model and views and notifies the views when the model changes state. The view is the piece that manages the visual display of the state represented by the model. A model can have more than one view.
View
- A view is some form of visualisation of the state of the model.
- The view manages the graphical and/or textual output to the portion of the bitmapped display that is allocated to its application.
- The view renders the contents of a model. It accesses enterprise data through the model and specifies how that data should be presented.
- The view is responsible for mapping graphics onto a device. A view typically has a one to one correspondence with a display surface and knows how to render to it. A view attaches to a model and renders its contents to the display surface.
Controller
- A controller offers facilities to change the state of the model. The controller interprets the mouse and keyboard inputs from the user, commanding the model and/or the view to change as appropriate.
- A controller is the means by which the user interacts with the application. A controller accepts input from the user and instructs the model and view to perform actions based on that input. In effect, the controller is responsible for mapping end-user action to application response.
- The controller translates interactions with the view into actions to be performed by the model. In a stand-alone GUI client, user interactions could be button clicks or menu selections, whereas in a Web application they appear as HTTP GET and POST requests. The actions performed by the model include activating business processes or changing the state of the model. Based on the user interactions and the outcome of the model actions, the controller responds by selecting an appropriate view.
- The controller is the piece that manages user interaction with the model. It provides the mechanism by which changes are made to the state of the model. below is an example of MVC pattern implementation .

Saturday, December 13, 2008
CodeIgniter Performance
Performance is usually the bane of any development effort. Things that you put together on a development server simply never seem to stand up to the pounding of real traffic. Once again, however, CodeIgniter comes to your aid with a set of profiling and benchmarking tools that allows you to see how your pages (and even sections of code) perform.
Profiling
If you’re curious about performance of any page, you can turn on profiling and get a detailed report of what’s happening. This is a useful thing to do before a site goes live.To turn on profiling, open your Welcome controller in an editor, and make the following change to the constructor:

Now visit the home page and scroll down. You should see a table giving details on how your application performed. You’ll see entries for controller load time, queries run, and other data. It should look something like Figure.

Compressing Output
One obvious way to speed up your home page is to turn on output compression. Doing so enables Gzip output compression for faster page loads. All you have to do is set $config[‘compress_output’] to TRUE in config.php, and CodeIgniter will test to see if the server its on supports Gzip compression. If so, then the server will use Gzip to speed things up.
There are two important things to keep in mind, however. Since not all browsers support Gzip compression, it will be ignored by those that can’t handle it. Don’t fret about this, though, because it is only the really old browsers that don’t use HTTP/1.1 or understand the Accept-Encoding header. Here’s a partial list of non-GZIP browsers:
❑ Netscape Navigator 3
❑ Netscape Communicator 4 (but only those before 4.06, and with errors after that version)
❑ Mozilla 0.9 (unless the user manually configures the browser to accept)
❑ Internet Explore 3.x and below
❑ Opera 3.5 and below
❑ Lynx 2.5 and below (some use separate Gzip command lines)
You might look at that list and think to yourself, “Isn’t it time for people to upgrade?” You’d be amazed at how long people hang on to their favorite browser. One more thing about compressing: If you have any white space at the end of your scripts, you’ll start serving blank pages. Make sure that you keep the ends of your scripts tidy.
Caching
CodeIgniter ’s caching engine allows you to take dynamically created pages and save them in their fully rendered states on the server, then reuse those fully rendered pages for a specific amount of time. For example, the first time a user hits a query-intensive page, the page is cached for X amount of time, and
all other visitors use the cached page until the cache expires.
Where are pages cached? Good question. They are written to the /system/cache folder that sits above your application. With high-traffic web sites, caching can give you huge boosts in performance in a short amount of time.
To put in caching, all you need to do is set a caching value for any controller function using the following command:

where X is the number of minutes you want the cache to remain active before it is deleted and reset.That’s it — there’s nothing else to load or configure because caching is part of the Output class and is therefore ready to be used in your application.
Turning Off Profiling
It is time to turn off profiling, as you don’t need it anymore. Simply erase the line from your controller,or set the profiler to FALSE.
Benchmarking
The Benchmark class can be used to mark start and end points in your code and to print out how much time (or how many resources) was used by that code. Benchmarking can be used in controllers, views, and models and are a great way to dig deeply into a performance-based problem.
To start off, open up your footer view (/system/application/views/footer.php), and add the following code to the file:
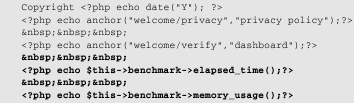
The elapsed_time() function will tell you how much time it took to render a page, from CodeIgniter framework initialization all the way through final output to the browser. The memory_usage() function will tell you how much memory was used.
Once you’ve loaded the view onto your site, visit one of the category pages. Remember, the home page is cached, so it’s better to visit an uncached page. You should see something like Figure.

According to the benchmarking functions, it took 0.07 seconds (give or take) to render the page, and it used 0 memory. (It could also be showing zero because your copy of PHP didn’t have --enable-memory- limit when it was compiled on the server. If that’s the case, and you want to show this kind of data, you will need to recompile PHP with the --enable-memory-limit flag set. In other words, having to reinstall PHP may or may not be worth your time, depending on the kind of visibility you want on profiling.) This kind of information is good, but what if you were trying to diagnose a more specific problem, like how long a specific query was taking? You could, for example, put the following markers down in your function:
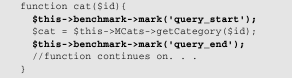
Then, in your footer view, you could use elapsed_time() to print out the results:

According to this example, the getCategory() model function is taking a total of 3/1,000-ths of a second to run.
Profiling
If you’re curious about performance of any page, you can turn on profiling and get a detailed report of what’s happening. This is a useful thing to do before a site goes live.To turn on profiling, open your Welcome controller in an editor, and make the following change to the constructor:

Now visit the home page and scroll down. You should see a table giving details on how your application performed. You’ll see entries for controller load time, queries run, and other data. It should look something like Figure.

Compressing Output
One obvious way to speed up your home page is to turn on output compression. Doing so enables Gzip output compression for faster page loads. All you have to do is set $config[‘compress_output’] to TRUE in config.php, and CodeIgniter will test to see if the server its on supports Gzip compression. If so, then the server will use Gzip to speed things up.
There are two important things to keep in mind, however. Since not all browsers support Gzip compression, it will be ignored by those that can’t handle it. Don’t fret about this, though, because it is only the really old browsers that don’t use HTTP/1.1 or understand the Accept-Encoding header. Here’s a partial list of non-GZIP browsers:
❑ Netscape Navigator 3
❑ Netscape Communicator 4 (but only those before 4.06, and with errors after that version)
❑ Mozilla 0.9 (unless the user manually configures the browser to accept)
❑ Internet Explore 3.x and below
❑ Opera 3.5 and below
❑ Lynx 2.5 and below (some use separate Gzip command lines)
You might look at that list and think to yourself, “Isn’t it time for people to upgrade?” You’d be amazed at how long people hang on to their favorite browser. One more thing about compressing: If you have any white space at the end of your scripts, you’ll start serving blank pages. Make sure that you keep the ends of your scripts tidy.
Caching
CodeIgniter ’s caching engine allows you to take dynamically created pages and save them in their fully rendered states on the server, then reuse those fully rendered pages for a specific amount of time. For example, the first time a user hits a query-intensive page, the page is cached for X amount of time, and
all other visitors use the cached page until the cache expires.
Where are pages cached? Good question. They are written to the /system/cache folder that sits above your application. With high-traffic web sites, caching can give you huge boosts in performance in a short amount of time.
To put in caching, all you need to do is set a caching value for any controller function using the following command:

where X is the number of minutes you want the cache to remain active before it is deleted and reset.That’s it — there’s nothing else to load or configure because caching is part of the Output class and is therefore ready to be used in your application.
Turning Off Profiling
It is time to turn off profiling, as you don’t need it anymore. Simply erase the line from your controller,or set the profiler to FALSE.
Benchmarking
The Benchmark class can be used to mark start and end points in your code and to print out how much time (or how many resources) was used by that code. Benchmarking can be used in controllers, views, and models and are a great way to dig deeply into a performance-based problem.
To start off, open up your footer view (/system/application/views/footer.php), and add the following code to the file:

The elapsed_time() function will tell you how much time it took to render a page, from CodeIgniter framework initialization all the way through final output to the browser. The memory_usage() function will tell you how much memory was used.
Once you’ve loaded the view onto your site, visit one of the category pages. Remember, the home page is cached, so it’s better to visit an uncached page. You should see something like Figure.

According to the benchmarking functions, it took 0.07 seconds (give or take) to render the page, and it used 0 memory. (It could also be showing zero because your copy of PHP didn’t have --enable-memory- limit when it was compiled on the server. If that’s the case, and you want to show this kind of data, you will need to recompile PHP with the --enable-memory-limit flag set. In other words, having to reinstall PHP may or may not be worth your time, depending on the kind of visibility you want on profiling.) This kind of information is good, but what if you were trying to diagnose a more specific problem, like how long a specific query was taking? You could, for example, put the following markers down in your function:

Then, in your footer view, you could use elapsed_time() to print out the results:

According to this example, the getCategory() model function is taking a total of 3/1,000-ths of a second to run.
Subscribe to:
Posts (Atom)